Data Scientist 커리큘럼
데이터로부터 인사이트를 발굴하고 비즈니스 가치를 창출하는 데이터 사이언티스트를 양성하는 과정입니다.
🎯 학습 목표
- 통계학과 수학적 기초를 바탕으로 한 데이터 분석 능력
- Python/R을 활용한 데이터 처리 및 시각화 기술
- 머신러닝과 딥러닝을 통한 예측 모델 구축
- 비즈니스 문제를 데이터 관점에서 해결하는 능력
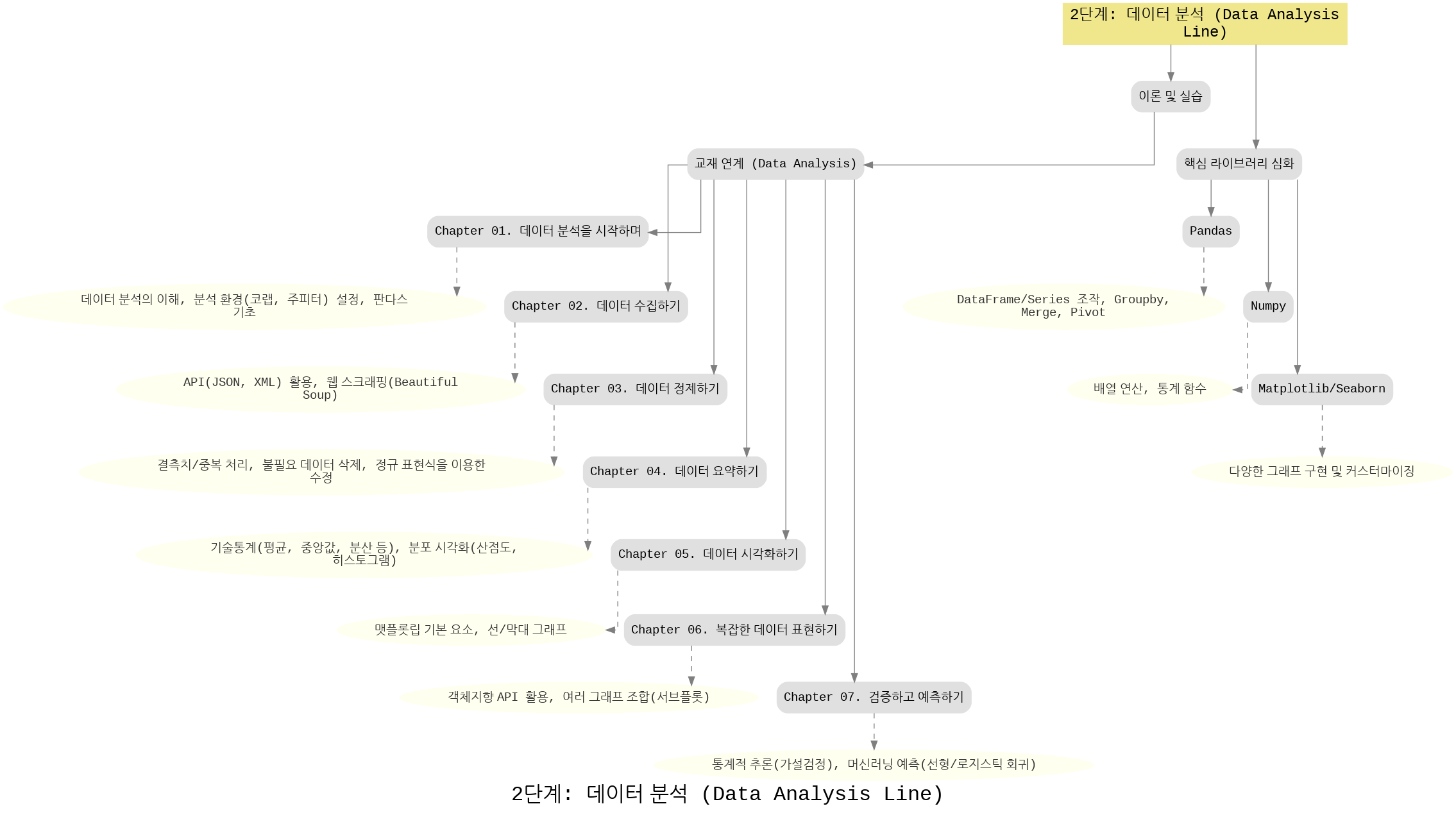
📚 커리큘럼 구성
1. 데이터 분석 시작하기
데이터 분석의 기본 개념을 배우고, 코랩/주피터 환경을 설정합니다.
- Python에서 Pandas를 활용해 데이터 프레임 다루기 시작.
- 분석 환경을 세팅하고, 간단한 데이터 입출력 실습.
2. 데이터 수집하기
데이터는 다양한 경로에서 얻습니다.
- API(JSON, XML) 활용법
- 웹 스크래핑(BeautifulSoup) 으로 데이터 수집
3. 데이터 정제하기
수집한 데이터는 그대로 쓰기 어렵습니다.
- 결측치, 중복 데이터 처리
- 불필요한 데이터 삭제
- 정규 표현식을 활용한 텍스트 정제
4. 데이터 요약하기
데이터의 기본 특성을 빠르게 파악하는 단계입니다.
- 기술통계(평균, 중앙값, 분산 등)
- 분포 시각화(산점도, 히스토그램)
5. 데이터 시각화하기
데이터를 눈으로 확인하며 패턴을 찾습니다.
- Matplotlib/Seaborn 기본 그래프 다루기
- 선/막대 그래프, 분포 그래프
6. 복잡한 데이터 표현하기
더 풍부한 분석을 위해 다양한 시각화 기법을 배웁니다.
- 객체지향 API 활용
- 여러 그래프 조합(서브플롯)
- 다양한 그래프 커스터마이징
7. 검증하고 예측하기
단순한 시각화를 넘어 통계적 추론과 머신러닝 기초로 연결됩니다.
- 가설 검정으로 데이터 의미 검증
- 선형/로지스틱 회귀로 데이터 예측 모델 만들기
핵심 라이브러리 심화
- Pandas: 데이터프레임/시리즈, Groupby, Merge, Pivot
- NumPy: 배열 연산, 통계 함수
- Matplotlib/Seaborn: 다양한 그래프 구현 및 시각화 커스터마이징

작성자: 황태검
문의처: academygum123@gmail.com