AI Developer 커리큘럼
인공지능 시스템을 설계하고 구현할 수 있는 AI 개발자를 양성하는 과정입니다.
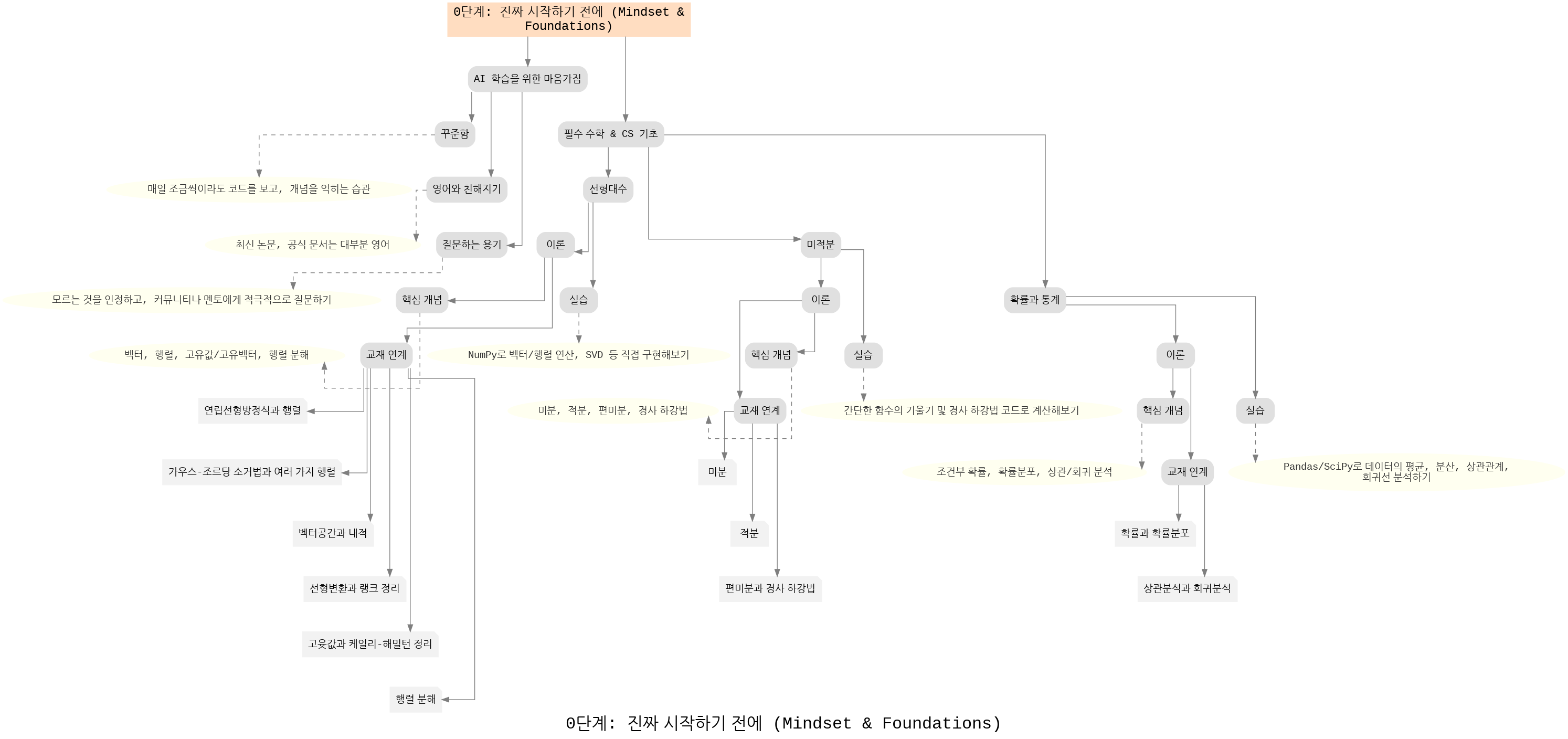
진짜 시작하기 전에
AI 학습을 시작하기 전 반드시 다져야 하는 기본적인 태도와 기초 지식 단계입니다. 이 단계에서는 꾸준히 공부하는 습관, 질문하는 태도, 영어 자료 활용 능력이 중요합니다.
- 꾸준함: 매일 조금씩이라도 코드를 보고 개념을 익히는 습관이 필요합니다.
- 영어와 친해지기: 최신 논문과 공식 문서는 대부분 영어로 작성되어 있기 때문에 영어 독해에 익숙해져야 합니다.
- 질문하는 용기: 모르는 것을 인정하고, 커뮤니티나 멘토에게 적극적으로 질문하면서 성장합니다.
- 수학 & CS 기초: 벡터, 행렬, 미적분, 확률통계 등은 AI의 언어이므로 반드시 기본기를 다져야 합니다.
-
실습 강조: NumPy, Pandas 등을 활용해 직접 벡터/행렬 연산, 확률 분석 등을 구현하며 이론을 몸으로 익히는 것이 중요하다.
- 수학과 프로그래밍은 목적이 아니라 도구입니다. 직접 계산하고 구현하면서 개념을 체득하세요!
0단계: AI 기초 수학 커리큘럼 설명
1. 선형대수
AI와 머신러닝의 뼈대를 이루는 수학입니다. 데이터와 모델을 다룰 때 가장 자주 쓰입니다.
- 벡터와 행렬: 데이터를 표현하는 기본 단위.
- 행렬 연산: 데이터 변환, 좌표 변환, 신경망 연산에 활용.
- 고유값/고유벡터: 차원 축소(PCA), 추천 시스템 등에서 핵심 개념.
- SVD: 이미지 처리, 차원 축소 등 응용.
2. 미적분
모델이 학습하는 과정을 이해하기 위한 핵심 도구입니다.
- 미분: 함수의 기울기를 계산, 경사 하강법(Gradient Descent)의 기초.
- 적분: 면적 계산, 확률 분포 이해에 활용.
- 편미분: 다변수 함수 최적화에서 필수.
- 체인룰(연쇄법칙): 역전파 알고리즘(Backpropagation)의 핵심.
확률과 통계
데이터의 불확실성을 다루고, 모델 예측을 평가하는 데 필요합니다.
- 확률 분포: 정규분포, 이항분포 등 데이터 패턴 이해.
- 조건부 확률 & 베이즈 정리: 스팸 필터, 추천 시스템 등에서 활용.
- 통계적 추론: 표본 → 모집단 일반화, 신뢰 구간/가설 검정.
- 상관 분석 & 회귀: 데이터 관계 파악 및 예측 모델링.
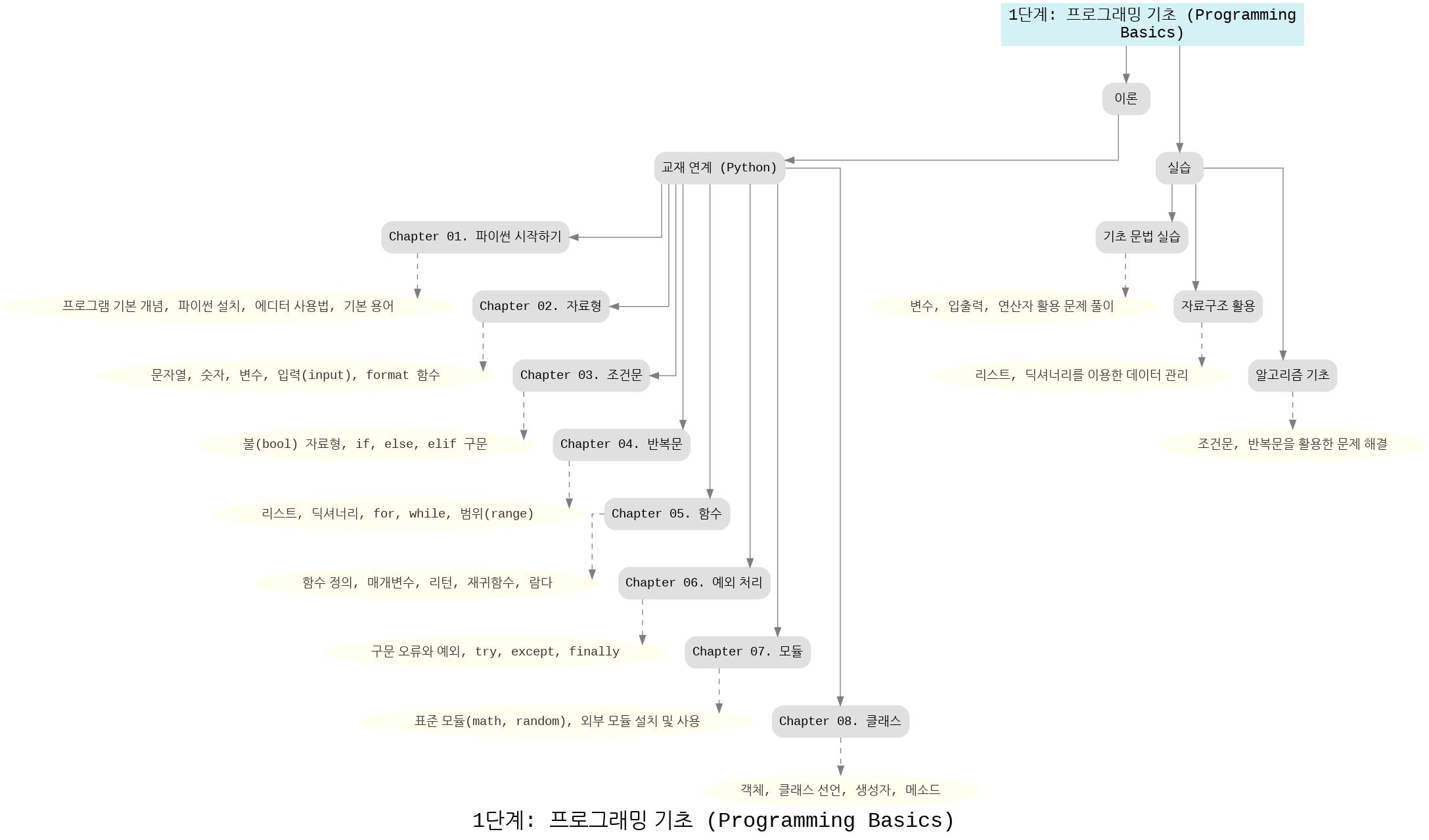
1단계: 프로그래밍 기초
이 단계에서는 Python을 중심으로 프로그래밍의 기본기를 다집니다. 문법 이해 → 간단한 문제 풀이 → 자료구조 활용 → 작은 프로젝트 순서로 학습이 진행됩니다.
- 기초 개념: 프로그램이 무엇인지, 파이썬 설치와 기본 용어를 익히며 출발합니다.
- 자료형: 숫자, 문자열, 불(bool), 리스트, 딕셔너리 등 데이터를 표현하는 다양한 방식 이해하기.
- 조건문 & 반복문: 프로그램의 논리 흐름을 제어하는 핵심 구조. (if, for, while 등)
- 함수: 복잡한 문제를 작은 단위로 나누어 해결하는 방법. 매개변수, 리턴값, 재귀 등을 다룹니다.
- 예외 처리: 코드 실행 중 발생할 수 있는 오류를 우아하게 다루는 법 (try,except).
- 모듈 & 라이브러리: 표준 모듈(math, random)과 외부 패키지를 불러와 사용하는 법.
- 클래스: 객체지향 프로그래밍의 출발점. 클래스 선언, 생성자, 메서드 학습.
교재


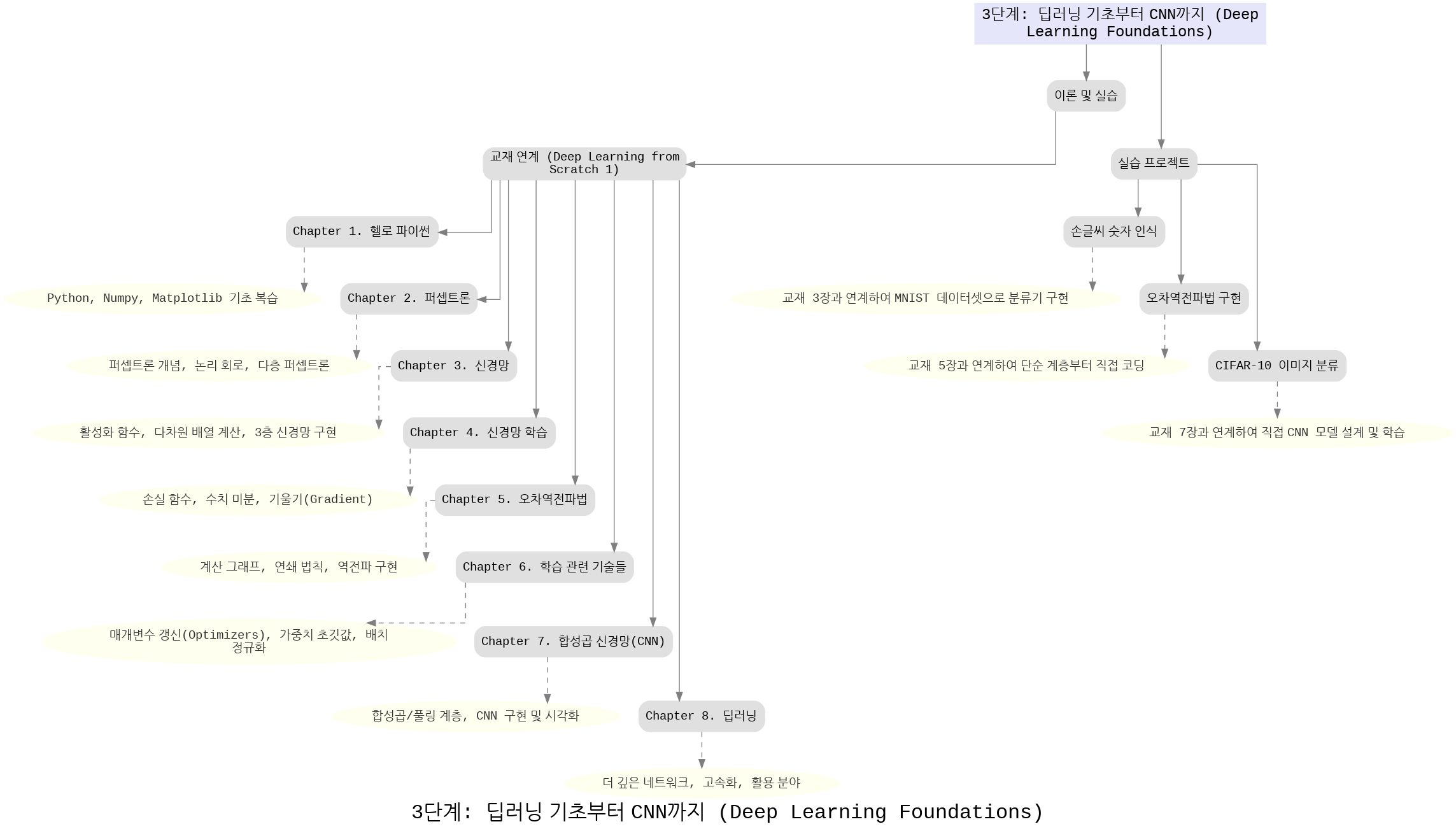
3단계: 딥러닝 기초부터 CNN 까지
이 단계는 딥러닝의 기초 이론부터 합성곱 신경망(CNN)까지 학습하는 과정입니다.
- 퍼셉트론, 신경망, 신경망 학습 이론을 차근차근 다지고,
- 오차역전파법, 학습 관련 기법, 옵티마이저, 배치 정규화 등 필수 기법을 학습합니다.
- 이후 합성곱 신경망(CNN) 으로 확장하여 손글씨 숫자 인식(MNIST), CIFAR-10 이미지 분류 실습을 통해 실제 딥러닝 모델을 설계하고 학습합니다.
이 단계는 딥러닝의 기본 원리와 CNN 기반 모델 구현 역량을 키우는 데 초점이 맞춰져 있습니다.
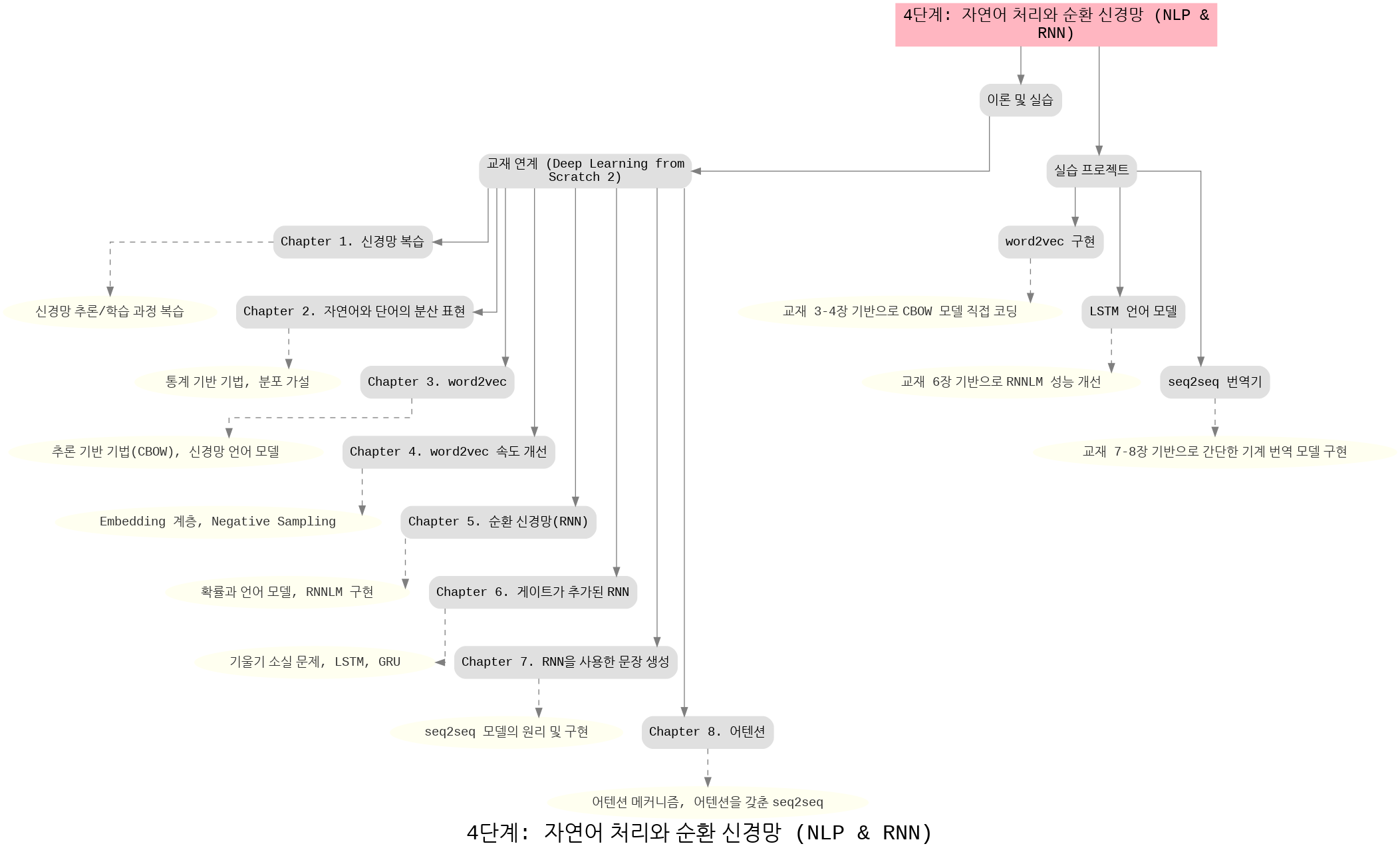
4단계: 자연어 처리와 순환 신경망
이 단계는 자연어 처리(NLP)와 순환 신경망(RNN) 기반 모델을 학습합니다.
- 단어 분산 표현(word2vec), 순환 신경망(RNN), LSTM, GRU 등을 학습하고,
- 언어 모델, 문장 생성, seq2seq 번역기, 어텐션 메커니즘까지 다룹니다.
- 실습 프로젝트로는 word2vec 구현, LSTM 기반 언어 모델, seq2seq 번역기 등을 직접 실습합니다.
이 단계는 자연어 처리의 기초부터 번역 모델 및 어텐션 기법까지 학습하여 실제 언어 모델을 설계·구현하는 데 중점을 둡니다.
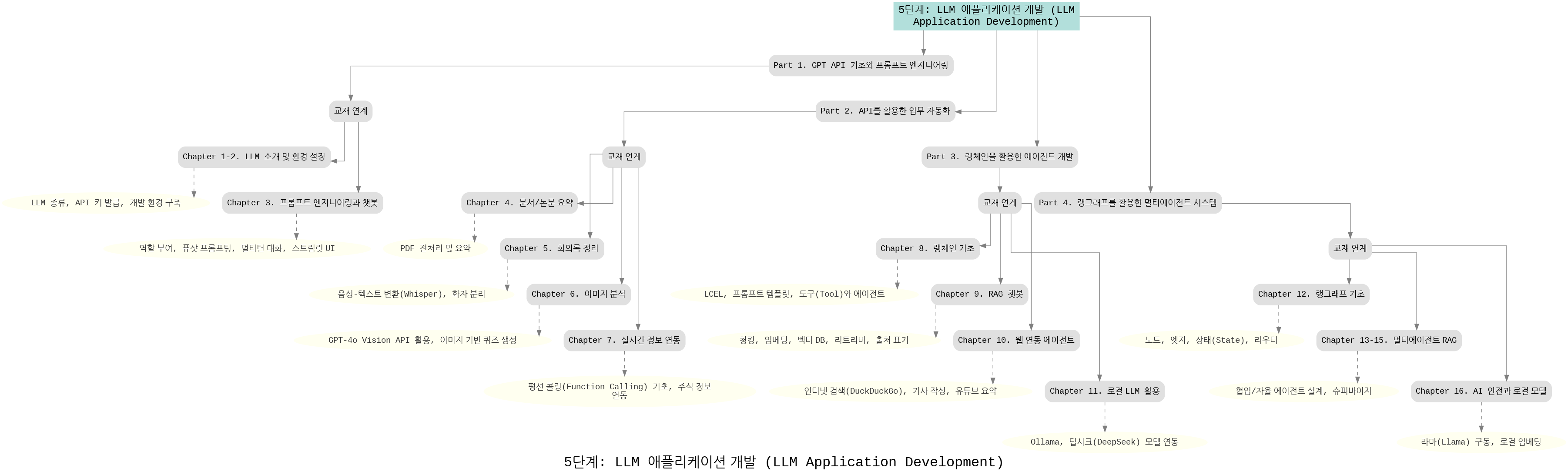
5단계: LLM 애플리케이션 개발
이 단계는 대규모 언어모델(LLM)을 실제 응용 서비스로 확장하는 과정입니다.
- 프롬프트 엔지니어링과 GPT API 기초부터 시작해 자동화된 API 활용, 랭체인을 이용한 에이전트 개발로 확장됩니다.
- 이후 문서 요약, 회의록 정리, 이미지 분석, 실시간 정보 연동 등 다양한 활용 사례를 다룹니다.
- 마지막으로 RAG 챗봇, 웹 자동화 에이전트, 로컬 LLM 활용, AI 안전과 규제 모델까지 심화 주제를 학습합니다.
즉, 이 단계는 실제 서비스형 AI 애플리케이션 개발을 위한 실전 로드맵을 제공합니다.
.jpg)


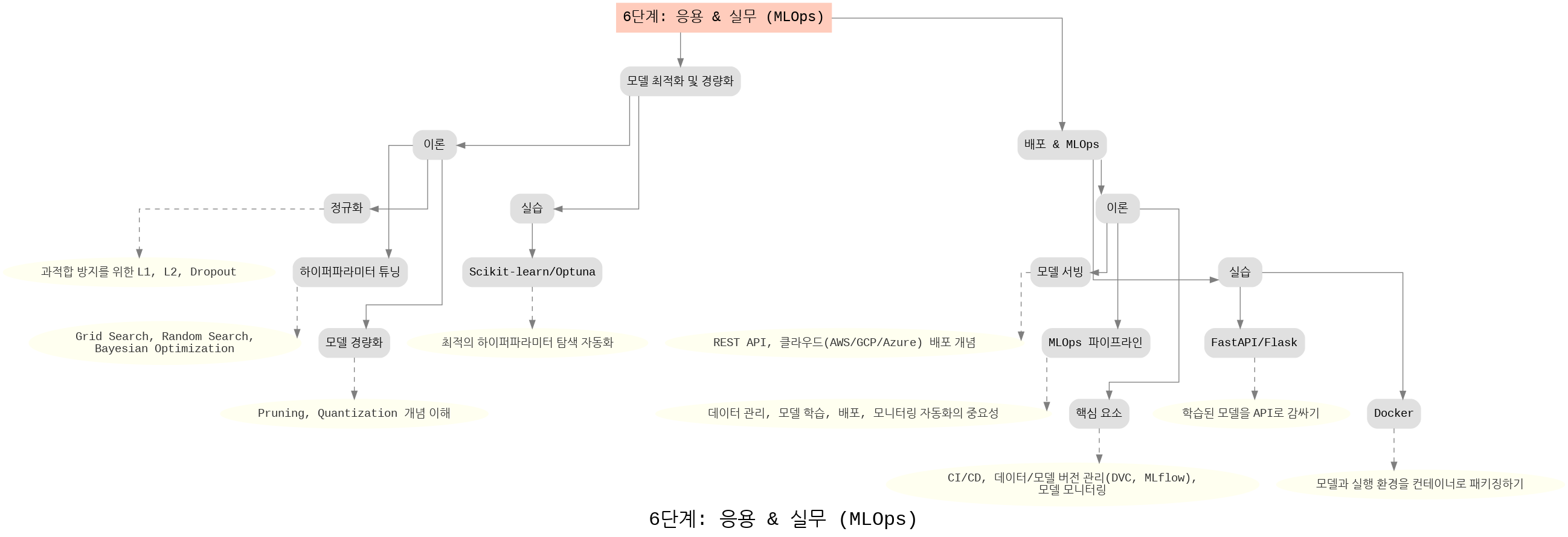
6단계: 응용 & 실무
이 단계는 MLOps(머신러닝 운영) 과정의 흐름을 정리한 구조입니다.
- 모델 최적화 및 경량화: 정규화, 하이퍼파라미터 튜닝, 모델 경량화(Pruning, Quantization) 등을 통해 성능 개선.
- 실습: Scikit-learn, Optuna 등을 활용해 자동화된 탐색과 최적화 실습.
- 배포 & MLOps: 모델 서빙(FastAPI/Flask), Docker 기반 패키징, 클라우드(AWS/GCP/Azure) 배포, MLOps 파이프라인 구축.
- 핵심 요소: CI/CD, 데이터 및 모델 버전 관리(DVC, MLflow), 자동화된 모니터링까지 포함.
즉, 머신러닝 모델을 실제 서비스 환경에서 운영 가능하도록 만드는 전 과정을 보여줍니다.
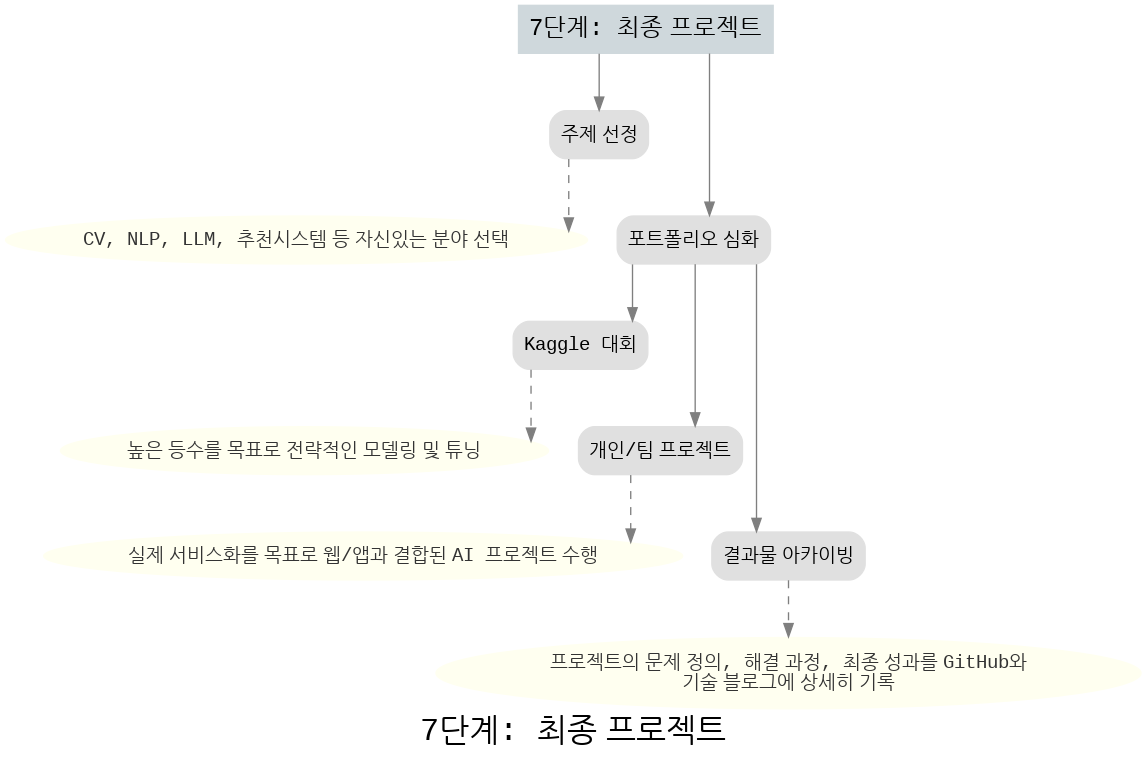
7단계: 최종 프로젝트
이 단계는 커리큘럼의 마지막 단계인 최종 프로젝트 진행 흐름을 보여줍니다.
- 주제 선정: CV, NLP, LLM, 추천시스템 등 관심 분야 선택.
- 포트폴리오 강화: Kaggle 대회 참가, 개인/팀 프로젝트 수행.
- 전략적 모델링: 높은 성능을 목표로 한 모델링 및 튜닝, 실제 서비스화를 고려한 프로젝트 설계.
- 결과물 아카이빙: 프로젝트 문제 정의, 해결 과정, 최종 성과를 GitHub 및 기술 블로그에 기록하여 포트폴리오로 활용.
즉, 지금까지 배운 내용을 종합하여 실제 활용 가능한 프로젝트를 완성하고 공개하는 단계입니다.
작성자: 황태검
문의처: academygum123@gmail.com